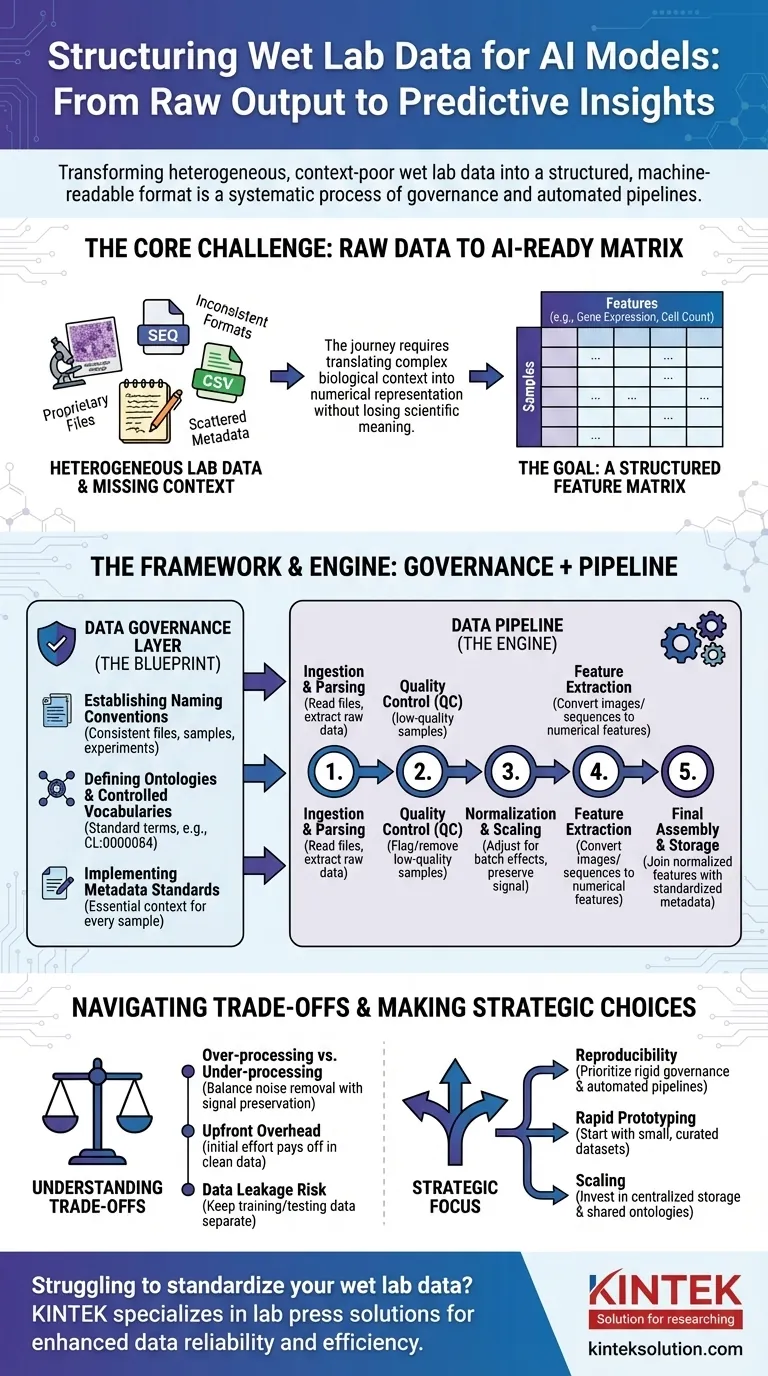
لإعداد بيانات المختبر الرطب للذكاء الاصطناعي، يجب تحويلها من حالتها الخام، التي غالبًا ما تكون غير متسقة، إلى تنسيق منظم وقابل للقراءة آليًا. هذه ليست خطوة واحدة بل عملية منهجية تتضمن حوكمة البيانات لإنشاء قواعد واضحة، تليها خطوط أنابيب البيانات التي تقوم بأتمتة تنظيف، وتوحيد، وهيكلة المخرجات التجريبية الخام في تنسيق متسق ومناسب لتدريب النموذج.
التحدي الأساسي لا يكمن ببساطة في إعادة تنسيق الملفات. بل يتعلق الأمر بترجمة منهجية للسياق البيولوجي المعقد—مثل الظروف التجريبية، وتاريخ العينة، وتقنيات القياس—إلى تمثيل رقمي منظم يمكن لنموذج الذكاء الاصطناعي التعلم منه دون فقدان المعنى العلمي الحاسم.

المشكلة الأساسية: من المخرجات الخام إلى البيانات الجاهزة للذكاء الاصطناعي
الرحلة من طاولة المختبر إلى نموذج تنبؤي محفوفة بتحديات البيانات. نادرًا ما تكون المخرجات الخام من الأجهزة العلمية جاهزة للاستخدام المباشر في خوارزمية الذكاء الاصطناعي، إن وجدت.
تغاير بيانات المختبر
تأتي بيانات المختبر الرطب في مجموعة واسعة من التنسيقات. يشمل ذلك كل شيء من الملفات الخاصة من أجهزة التسلسل والمجاهر إلى ملفات CSV البسيطة من قارئات الأطباق، ولكل منها هيكله وخصوصياته.
ومع ذلك، يتطلب نموذج الذكاء الاصطناعي تنسيقًا موحدًا.
لعنة السياق المفقود
المعلومات الحيوية، أو البيانات الوصفية (metadata)، غالبًا ما تكون مبعثرة. قد تكون في دفتر ملاحظات عالم، أو جدول بيانات منفصل، أو ببساطة في ذهنه. بدون هذا السياق (مثل: أي دواء تم تطبيقه، درجة الحرارة، خط الخلية المستخدم)، تكون البيانات الرقمية بلا معنى.
الهدف: مصفوفة الميزات
في النهاية، تحتاج معظم نماذج الذكاء الاصطناعي إلى بيانات في مصفوفة الميزات. هذا جدول بسيط حيث تمثل الصفوف عينات فردية (مثل: مريض، بئر مزرعة خلايا) وتمثل الأعمدة ميزات (مثل: مستويات التعبير الجيني، قياسات شكل الخلية، تركيزات البروتين).
إطار عمل للتوحيد القياسي: طبقة حوكمة البيانات
قبل أن تتمكن من بناء خطوط أنابيب آلية، يجب عليك وضع القواعد. هذه هي حوكمة البيانات—المخطط الذي يضمن الاتساق عبر جميع التجارب والفرق. إنها الخطوة الأكثر أهمية والتي غالبًا ما يتم إغفالها.
وضع اتفاقيات التسمية
إحدى القواعد البسيطة والقوية هي فرض مخطط تسمية متسق للملفات والعينات والتجارب. وهذا يسمح بربط البيانات وتتبعها برمجيًا من مصدرها إلى التحليل النهائي.
تحديد الأنطولوجيات والمفردات المضبوطة
توفر الأنطولوجيا مجموعة قياسية من المصطلحات لوصف الكيانات البيولوجية. على سبيل المثال، بدلاً من السماح بـ "الخلايا التائية"، "الخلايا الليمفاوية التائية"، و"Tcell"، تفرض المفردات المضبوطة مصطلحًا واحدًا، مثل CL:0000084 من أنطولوجيا الخلية.
هذا يمنع الغموض ويضمن أن البيانات من التجارب المختلفة قابلة للمقارنة حقًا.
تطبيق معايير البيانات الوصفية
يجب عليك تحديد الحد الأدنى من البيانات الوصفية التي يجب جمعها لكل عينة على حدة. يتضمن ذلك غالبًا مصدر العينة، والظروف التجريبية، وإعدادات الجهاز، والتاريخ. تضمن هذه القاعدة عدم تحول أي نقطة بيانات إلى يتيمة، منفصلة عن سياقها.
محرك التحويل: بناء خط أنابيب البيانات
مع وجود قواعد الحوكمة، يمكنك بناء خط أنابيب البيانات. هذه سلسلة من الخطوات البرمجية المؤتمتة التي تحول البيانات الخام إلى مصفوفة الميزات النهائية الجاهزة للذكاء الاصطناعي.
الخطوة 1: استيعاب البيانات وتحليلها
المهمة الأولى لخط الأنابيب هي العثور على ملفات البيانات الخام وقراءتها. تتضمن هذه الخطوة كتابة محللات محددة لتنسيق إخراج كل جهاز لاستخراج القياسات الأساسية وأي بيانات وصفية مرتبطة بها.
الخطوة 2: مراقبة الجودة (QC)
ليست كل البيانات جيدة. يجب أن يقوم خط الأنابيب تلقائيًا بوضع علامة على العينات منخفضة الجودة أو إزالتها بناءً على مقاييس محددة مسبقًا، مثل عدد الخلايا المنخفض في تجربة تصوير أو جودة القراءة الضعيفة من جهاز تسلسل.
الخطوة 3: التسوية والقياس
غالبًا ما تحتوي القياسات من دفعات أو أطباق مختلفة على اختلافات تقنية. التسوية (Normalization) هي خطوة حاسمة تقوم بتعديل البيانات لجعل القياسات قابلة للمقارنة عبر التجارب، وإزالة الضوضاء التقنية مع الحفاظ على الإشارة البيولوجية.
الخطوة 4: استخراج الميزات
غالبًا لا تكون البيانات الخام في تنسيق الميزات. يجب معالجة الصورة، على سبيل المثال، لاستخراج ميزات رقمية مثل حجم الخلية وشكلها وشدتها. قد يتم تحويل تسلسل الحمض النووي إلى متجه تردد k-mer. تحول هذه الخطوة البيانات المعقدة إلى أرقام يمكن للذكاء الاصطناعي استخدامها.
الخطوة 5: التجميع والتخزين النهائي
أخيرًا، يجمع خط الأنابيب الميزات المعيارية مع البيانات الوصفية الموحدة. يؤدي هذا إلى إنشاء مصفوفة الميزات النهائية والنظيفة، والتي يتم حفظها بعد ذلك في تنسيق مستقر وقابل للاستعلام (مثل Parquet أو قاعدة بيانات) لتدريب النموذج.
فهم المقايضات
هيكلة البيانات ليست عملية محايدة. كل خيار تتخذه يمكن أن يؤثر على أداء النموذج النهائي وتفسيره.
الإفراط في المعالجة مقابل النقص في المعالجة
قد تؤدي التسوية أو التصفية القوية أحيانًا إلى إزالة إشارات بيولوجية دقيقة ولكنها مهمة. وعلى العكس من ذلك، فإن الفشل في إزالة الضوضاء التقنية سيضمن أن يتعلم نموذجك من آثار تجريبية بدلاً من البيولوجيا. هذا توازن مستمر.
التوحيد القياسي يخلق تكلفة أولية
يتطلب تطبيق حوكمة البيانات جهدًا أوليًا كبيرًا وموافقة من الفريق بأكمله. قد يبدو الأمر وكأنه يبطئ البحث في البداية، لكنه يؤتي ثماره بشكل كبير من خلال منع شهور من أعمال التنظيف لاحقًا.
خطر تسرب البيانات
تتمثل إحدى وظائف خط الأنابيب الحاسمة في فصل بيانات التدريب والاختبار. إذا تم استخدام معلومات من مجموعة الاختبار (مثل توزيعها العام) لتسوية مجموعة التدريب، فإن أداء نموذجك سيتضخم بشكل مصطنع وسيفشل في العالم الحقيقي.
اختيار الخيار الصحيح لهدفك
يجب أن يسترشد نهجك في هيكلة البيانات بهدفك النهائي.
- إذا كان تركيزك الأساسي هو قابلية التكرار: أعط الأولوية للحوكمة الصارمة للبيانات وخطوط الأنابيب المؤتمتة بالكامل والمتحكم فيها بالإصدار من اليوم الأول.
- إذا كان تركيزك الأساسي هو النماذج الأولية السريعة: ابدأ بمجموعة بيانات صغيرة ومنسقة يدويًا للتحقق من صحة نهج الذكاء الاصطناعي الخاص بك قبل الاستثمار في خط أنابيب واسع النطاق.
- إذا كان تركيزك الأساسي هو التوسع عبر مؤسسة كبيرة: استثمر بكثافة في التخزين المركزي للبيانات، والأنطولوجيات المشتركة، ومكونات خط الأنابيب المشتركة لمنع صوامع البيانات.
في النهاية، التعامل مع بياناتك بنفس الدقة التي تتعامل بها مع تجارب المختبر الرطب هو أساس بناء ذكاء اصطناعي بيولوجي ناجح وموثوق.
جدول ملخص:
| الخطوة | الإجراء الرئيسي | الغرض |
|---|---|---|
| حوكمة البيانات | وضع اتفاقيات التسمية، والأنطولوجيات، ومعايير البيانات الوصفية | ضمان الاتساق وقابلية المقارنة عبر التجارب |
| خط أنابيب البيانات | استيعاب، تحليل، مراقبة جودة، توحيد، استخراج ميزات، تجميع | أتمتة تحويل البيانات الخام إلى مصفوفة ميزات جاهزة للذكاء الاصطناعي |
| المقايضات | الموازنة بين الإفراط في المعالجة والنقص في المعالجة، إدارة التكاليف الأولية | تحسين أداء النموذج وتجنب تسرب البيانات |
هل تواجه صعوبة في توحيد بيانات المختبر الرطب لديك للذكاء الاصطناعي؟ تتخصص KINTEK في آلات الضغط المختبرية، بما في ذلك مكابس المختبر الأوتوماتيكية، والمكابس المتساوية الضغط، ومكابس المختبر الساخنة، لخدمة المختبرات بهدف تعزيز موثوقية البيانات وكفاءة التجربة. دعنا نساعدك في تحقيق نتائج متسقة—اتصل بنا اليوم لمناقشة احتياجاتك واكتشاف كيف يمكن لحلولنا دعم أبحاثك المدفوعة بالذكاء الاصطناعي!
دليل مرئي